Understanding Autoencoders and GANs for Anomaly Detection
In cybersecurity, anomaly detection is critical when it comes to finding threats in an environment. Whether we’re talking about firewalls, endpoint detection and response (EDR) solutions, or user entity behavior analytics (UEBA) solutions, you can’t escape the use of anomaly detection within modern cybersecurity practice. Most people know the concept of anomaly detection, and a lot of people know that artificial intelligence can be used for anomaly detection. However, a lot of people aren’t aware of the means by which it can be performed.
Anomaly detection stems from the roots of data science. Data science can be broadly defined as the application of mathematics to data in order to classify data or predict future data. For anomaly detection, statistical methods are used to first understand what is normal for the data. This “normal” can be established through different means such as clustering algorithms (grouping similar data points together and determining what data points fall outside the clusters), and density algorithms (the data points that fall in regions where a lot of other data points exist is normal, and data points that fall outside these regions are outliers). Both of these methods have their pros and cons, but further development in artificial intelligence has brought about anomaly detection using deep learning methods, which are the same learning methods that are used to develop large language models like ChatGPT.
Deep learning works quite well for anomaly detection within cybersecurity because of the vast amounts of data that are generated by cybersecurity tools. Deep learning methods improve when you have more data points off which to train, so applying deep learning anomaly detection to cybersecurity goes hand in hand. Some of the more popular deep learning methods for anomaly detection involve autoencoders and generative adversarial networks (GANs).

Autoencoder visualization, credit to https://www.mygreatlearning.com/blog/autoencoder/
At a high level, autoencoders work by taking large datasets and “compressing” the data down into what’s known as a latent space. This latent space can be defined as a representation of the data in a compressed form. The autoencoder then “decompresses” the data back to its original form. The idea behind autoencoders for anomaly detection is that if the autoencoder receives data similar to the data on which it’s trained, then the autoencoder’s compression and decompression process will produce a result that is similar to the original data. If it receives an anomalous data point, then the autoencoder’s compression and decompression process will produce a result that is not similar to the original data. The difference between the original data and the compressed/decompressed data can be measured, and this difference is known as the “loss”. If the loss is low, then it’s a normal data point. If the loss is high, then it’s an anomalous data point. Therefore, you can set a threshold for this loss that dictates whether a data point is normal or anomalous. The threshold value depends on the dataset, so you have to do some experimenting to see what the threshold is for your respective dataset.
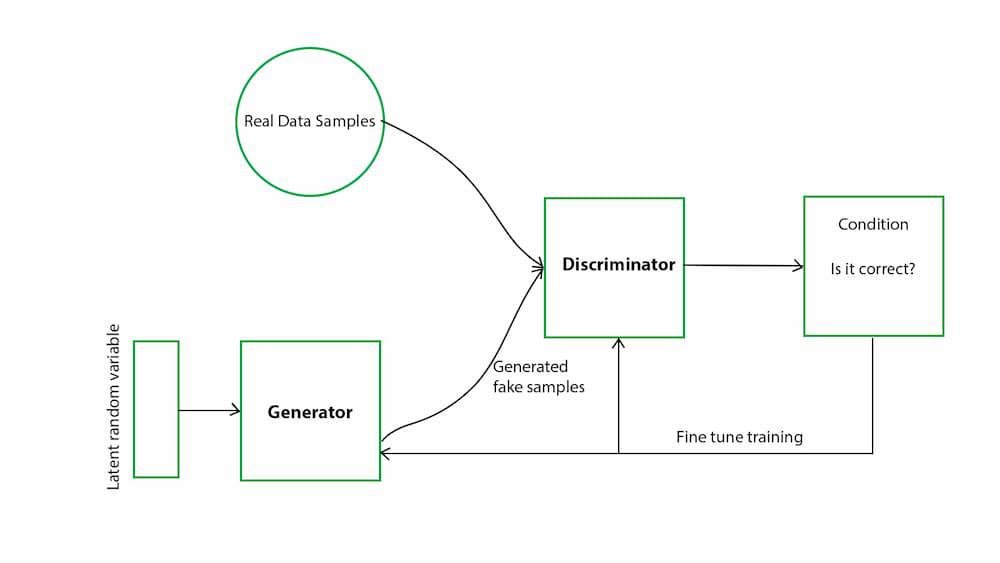
GAN visualization, credit to https://www.geeksforgeeks.org/generative-adversarial-network-gan/
GANs, or generative adversarial networks, tackle anomaly detection differently. GANs have two parts to them: the generator and the discriminator. The generator is trained to produce fake data that looks similar to the original dataset, and the discriminator is trained to distinguish values from the original dataset and what the generator produces. The trick here is that as the training process occurs, the generator becomes better and better at producing fake data, which therefore improves the discriminator at distinguishing the original dataset from the fake values. At the end of the training process, you end up with a discriminator that does a good job of distinguishing what is real and what is fake, and consequently becomes an anomaly detector for your dataset. If you feed the discriminator anomalous values, then the discriminator will be able to tell you how “fake”, or anomalous, the data point is.
Depending on your dataset, you’ll have varying results with whether you use autoencoders or GANs. For my own use cases, GANs have worked better for me, as the training process was faster and produced more accurate results. However, you may achieve opposite results to myself due to a number of factors, depending on how your data is composed, the hyperparameters of your models, etc.
I highly recommend reading https://ff12.fastforwardlabs.com/ if you’re interested in learning more about anomaly detection as well as open source libraries that can be used for anomaly detection. If you’d like to see how this can be applied to your cybersecurity data, contact QFunction to see a demo of how this can be implemented in your SIEM!